- 不思议迷宫m14前瞻攻略
- 有什么好玩儿的手游推荐吗
- 泰坦之旅米诺斯迷宫巨大机器人怎么打
- 你今天看了什么电影呀
- GAMEBOY游戏机经典游戏有哪些
- 深度强化学习领域近期有什么新进展
- 可以推荐几款烧脑游戏吗
- 机器人历险记78关如何通过
- 不思议迷宫军团科技怎么拿
- 谁能帮忙推荐一下,好看的电视剧或电影
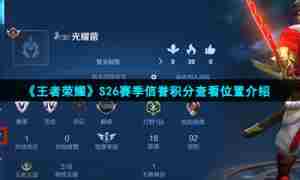
不思议迷宫m14前瞻攻略
不思议迷宫m14攻略
有什么好玩儿的手游推荐吗
Kingdom 一坨像素稀饭游戏,不过游戏性很高,与其说他是策略冒险类,我觉得这游戏更像一个塔防游戏,大概玩法就是增强自己的王国,有很强代入感,二一个是你能看到非常柔美的像素风景和听到上古世纪风格的柔美BGM
Corocco 说白点,一个石头模拟器,但你可以滚动这颗石头去做任何想做的事情,游戏是那种固定的关卡流程,你需要滚动石头来完成小谜题,还需要用石头去锤人,没错,扮演一颗石头去锤人,游戏画风非常小清新,音乐很舒适,适合休闲
神回避1 神回避2 游戏藏起来了等系列 日和风的竖版解密游戏,游戏中的谜题相当无厘头且蛋痛,但很有趣,也是小清新游戏,适合休闲
无尽之剑系列 史诗级的手游 类似于欧洲的中世纪剑与魔法时代 但游戏操作大概就只有划屏了,就像水果忍者一样
Happy Wheels和极限摩托 简单粗暴非常爽快的横版障碍闯关游戏 需要控制力度和一定的智商
泰坦之旅米诺斯迷宫巨大机器人怎么打
站在从二层刚上来的楼梯口向上走1步(碰到墙走不动)——向左走22步(碰到墙走不动为止)——向下走 2步(碰到墙走不动为止)——向右走4步——向下走11步(碰到墙走不动为止)——向右走9步(碰到墙走不动为止)——向上走8步(碰到开关B为止)—— 出现对话框,选择拉下开关,透明魔法解除。(记住看主角的动作数步数)扳下左侧的会导致主角变成隐形人,不过只要离开这一层就会自动解除隐形了。在南侧找到门上楼。这一层的宝箱比较多,其中一个里可以找到特殊防具。
你今天看了什么电影呀
在手机上看电影现在也需要有时间啊!?
天天的瞎忙。
GAMEBOY游戏机经典游戏有哪些
GAMEBOY,童年是真的喜欢啊,我记得是小学的时候得到了人生中的第一台gbc机子,还是黑白的,gbc的游戏我还真玩了不少,那么今天我就给你推荐几款我个人觉得非常经典的游戏
1.口袋妖怪系列,口袋妖怪是我在gbc上玩的第一款游戏,玩的蓝版,惊叹掌机上也能玩rpg,一只喷火龙通关,我想很多小伙伴也和我有一样的经历吧,但是我觉得gbc最好玩的口袋妖怪还是金银版本,两张地图,各种隐藏地点,可玩性更强
2.勇者斗恶龙怪兽仙境系列,带着自己的怪兽冒险,途中还可以收服新的怪兽,这个游戏最大的亮点就是怪兽合成系统,两个怪兽合成一个新的更强的怪兽,总想试试两个强大的怪兽合成能变出什么东西,这也是我在gbc上最喜欢玩的游戏
3.牧场物语,当时牧场物语那种游戏是非常吸引人的,种植东西,钓鱼,养羊,养鸡,玩家代入感极强,看着自己亲手打造的牧场,非常有成就感
以上就是我觉得gbc上比较经典的游戏,当然gbc上还有很多好游戏,欢迎大家补充,望采纳
深度强化学习领域近期有什么新进展
深度强化学习是近年来人工智能领域内最受关注的研究方向之一,并已在游戏和机器人控制等领域取得了很多耀眼的成果。DeepMind 的工程师 Joyce Xu 近日发表了一篇博客文章,介绍了深度强化学习领域的一些近期进展,其中涉及到分层式强化学习、记忆、注意机制、世界模型和想象等方向。
我觉得,深度强化学习最让人喜欢的一点是它确实实在难以有效,这一点不同于监督学习。用神经网络来解决一个计算机视觉问题可能能达到 80% 的效果;而如果用神经网络来处理强化学习问题,你可能就只能眼睁睁地看着它失败——而且你每次尝试时遭受的失败都各不相同。
强化学习领域内的很多最大的挑战都围绕着两大问题:如何有效地与环境交互(比如探索与利用、样本效率),以及如何有效地从经历中学习(比如长期信用分配、稀疏奖励信号)。在这篇文章中,我希望探讨深度强化学习领域内试图解决这些挑战的几个近期研究方向,并且还会将其与人类认知进行优雅简洁的对比。具体而言,我将谈到:
分层式强化学习
记忆和预测建模
将无模型方法与基于模型的方法组合到一起
本文首先将简要介绍两个代表性的深度强化学习算法——DQN 和 A3C,以为后文提供能够作为参考的直观知识,然后我们会深入探讨几篇近期的论文和研究突破。
DQN 和 A3C/A2C
声明:我假设读者已经对强化学习有一定的基本了解了(因此这里不会提供有关这些算法的深度教程),但就算你对强化学习算法的工作并不完全了解,你应该也能阅读后文的内容。
DeepMind 的 DQN(深度 Q 网络)是将深度学习应用于强化学习的最早期突破性成功之一。其中使用了一个神经网络来学习用于经典 Atari 游戏的 Q 函数,比如《乒乓球》和《打砖块》,从而让模型可以直接根据原始像素输入得出应该采取的动作。
从算法上看,DQN 直接源自经典的 Q 学习技术。在 Q 学习中,一个状态-动作对的 Q 值(即 quality 值)是通过基于经历的迭代式更新来估计的。从本质上讲,对于某个状态下我们可采取的每个动作,我们都可以使用收到的即时奖励和对新状态的价值估计来更新原来的状态-动作对的价值估计:
DQN 的训练是最小化时间差分误差(TD-error)的 MSE(均方误差),如上所示。DQN 使用了两个关键策略来使 Q 学习适用于深度神经网络,而且这两个策略也在后续的深度强化学习研究中得到了成功的应用。这两个策略为:
经历重放(experience replay),其中每个状态/动作转换元组 (s, a, r, s』) 都存储在一个记忆「重放」缓存冲,并会被随机采样以用于训练网络,从而可实现对训练数据的重复使用和去除连续轨迹样本中的相关性。
使用一个单独的目标网络(即上式中的 Q_hat 部分)来实现训练的稳定,所以 TD 误差不是根据源自训练网络的不断变化的目标计算的,而是根据由一个基本固定的网络所生成的稳定目标计算的。
在那之后,DeepMind 的 A3C(Asynchronous Advantage Actor Critic)和 OpenAI 的同步式变体 A2C 也非常成功地将深度学习方法推广到了 actor-critic 方法上。
actor-critic 方法将策略梯度方法与一种学习后的价值函数结合到了一起。对于 DQN 方法,我们仅有学习后的价值函数(即 Q 函数),而我们遵循的「策略」只是简单地在每个步骤取能最大化 Q 值的动作。使用 A3C 和使用其它 actor-critic 方法一样,我们会学习两个不同的函数:策略(即 actor)和价值(即 critic)。策略函数是基于采取该动作的当前估计优势(advantage)来调整动作概率,而价值函数则是基于经历和后续策略收集到的奖励来更新该优势:
从上面的更新可以看出,价值网络会学习一个基线状态值 V(s_i;θ_v),我们可以将其与我们的当前奖励估计 R 进行比较,从而得到「优势」;策略网络则会通过经典的 REINFORCE 算法根据该优势调整动作的对数概率。
A3C 真正的贡献在于其并行化和异步化的架构:多个 actor 学习器被分派到不同的环境实例中;它们全都会与环境进行交互并收集经历,然后异步地将它们的梯度更新推送到一个中心的「目标网络」(一个借用自 DQN 的思路)。之后,OpenAI 的 A2C 研究表明异步实际上对性能没有贡献,而且事实上还会降低样本效率。对这些架构的详细解释已经超出了本文的覆盖范围,但如果你和我一样对分布式智能体感兴趣,那一定要看看 DeepMind 的 IMPALA,这是一种非常有用的设计范式,可用于实现对学习的扩展:。
DQN 和 A3C/A2C 都是非常强大的基线智能体,但是在面对更加复杂的任务、严重的部分可观察性和/或动作与相关奖励信号之间存在较长延迟时,这些智能体往往难以为继。因此,强化学习研究中有一整个子领域在致力于解决这些问题。接下来我们看看其中一些优秀的研究。
分层式强化学习(HRL)
分层式强化学习是一类从多个策略层学习的强化学习方法,其中每一层都负责控制不同层面的时间和行为抽象。最低层面的策略负责输出环境动作,让更高层面的策略可以操作更抽象的目标和更长的时间尺度。
为什么这种方法很吸引人?首先也是最重要的一点是在认知方面,有很多研究都认为人类和动物行为都基于分层式结构。这在日常生活中有直观的体现:当我决定做一顿饭时(实际上我基本从不做饭,但为了合理论述,就假设我是一个负责的人类吧),我会将这一任务分成多个更简单的子任务(切蔬菜、煮面条等),但绝不会忽视我要做饭的总体目标;我甚至还能切换不同的子任务来完成同样的目标,比如不煮面条而是蒸饭。这说明真实世界任务中存在固有的层次结构和组合性质,因此可将简单的基础动作串接、重复或组合起来以完成复杂的工作。近些年的一些研究甚至发现 HRL 组件与前额叶皮质中的特定神经结构之间存在直接的相似性。
从技术方面看,HRL 尤其引人注目,因为它能帮助解决我们前文提到的第二个问题的两大挑战:如何有效地从经历中学习(比如长期信用分配、稀疏奖励信号)。在 HRL 中,因为低层策略是基于高层策略分配的任务从内在奖励中学习的,所以尽管奖励稀疏,基础任务仍可得以学习。此外,高层策略发展起来的时间抽象让我们的模型可以根据时间上延展的经历来处理信用分配问题。
所以 HRL 的工作是怎样的?目前有一些各不相同的方法都能实现 HRL。Google Brain 近期的一篇论文采用了一种尤其清晰和简单的方法,并为数据高效型训练引入了一些很好的离策略修正方法。他们的模型名为 HIRO:。
μ_hi 是高层面的策略,其为低层面的策略输出需要实现的「目标状态」。μ_lo 是低层面的策略,输出环境动作以试图达成其目标状态观察。
其设计思路是有两个策略层。高层策略的训练目标是最大化环境奖励 R。每 c 个时间步骤,高层策略都会采样一个新动作,这是低层策略所要达成的「目标状态」。低层策略的训练目标是选取合适的环境动作,使其能产生类似于给定目标状态的状态观察。
举一个简单的例子:假设我们在训练一个机器人以特定的顺序堆叠彩色方块。我们仅有单个奖励 1 在任务成功最终完成时给出,所有其它时间步骤的奖励都是 0。直观地说,高层策略负责提出所要完成的必要子目标:也许它输出的第一个目标状态是「观察到一个红色方块在你面前」,第二个目标状态可能是「观察到蓝色方块在红色方块旁边」,然后是「观察到蓝色方块在红色方块上面」。低层策略在环境中探索,直到其找到用于产生这些观察结果所必需的动作序列,比如选取一个蓝色方块并将其移动到红色方块之上。
HIRO 使用了 DDPG(深度确定性策略梯度)训练目标的一种变体来训练低层策略,其内在奖励被参数化为了当前观察与目标观察之间的距离:
DDPG 是又一种影响深远的深度强化学习算法,其将 DQN 的思想扩展到的连续动作空间。这也是一种 actor-critic 方法,使用策略梯度来优化策略;但不同于 A3C 中那样根据优势来优化策略,它是根据 Q 值来进行优化。因此在 HIRO 中,所要最小化的 DDPG 邻近误差就变成了:
同时,为了使用离策略的经历,高层策略使用了离策略修正来进行训练。其思想是:为了提升样本效率,我们希望使用某种形式的重放缓存,就像 DQN 一样。但是,过去的经历不能直接用于训练高层策略。这是因为低层策略会持续学习和改变,所以就算我们设置了与过去经历一样的目标,低层策略还是可能表现出不同的动作/转换。HIRO 中提出的离策略修正是为了回溯性地修改在离策略经历中看到的目标,从而最大化所观察到的动作序列的可能性。换句话说,如果重放经历表明过去的智能体采取动作 (x,y,z) 能达成目标 g,那么我们就寻找一个目标 g̃,使得它能让当前的智能体最有可能采取同样的动作 (x,y,z),即能够最大化该动作序列的对数概率(如下式)的动作。
然后使用 DDPG 的一种变体在这些动作、新目标和环境奖励 R 上训练高层策略。
HIRO 当然不是唯一一种 HRL 方法。FeUdal 网络是一种更早的相关研究(),其使用了一个学习到的「目标」表征而不是原始的状态观察。实际上,研究中的很多变体都源自学习有用的低层子策略的不同方法;很多论文都使用了辅助的或「代理的」奖励,还有一些其它研究实验了预训练或多任务训练。不同于 HIRO,这些方法中很多都需要某种程度的人工设计或领域知识,这从本质上限制了它们的通用性。近期也有研究在探索使用基于群体的训练(PBT,),这是另一个我个人很喜欢的算法。本质上讲,内部奖励被当作了附加超参数进行处理,通过在训练过程中「演进」群体,PBT 能学习到这些超参数的最优演化。
HRL 是当前一个非常受欢迎的研究领域,而且也非常容易与其它技术组合到一起,比如这篇论文将 HRL 与模仿学习结合了起来:。但是,HRL 的核心只是一个非常直观的思想。HRL 是可扩展的,具备神经解剖学上的相似性,能解决强化学习领域内的一些基本问题。但和其它优秀的强化学习方法一样,它的训练难度颇高。
记忆和注意
现在来谈谈用于解决长期信用分配和稀疏奖励信号问题的其它方法。具体而言,我们要说的是最明显的方法:让智能体真正擅长记忆事物。
深度学习中的记忆总是很有意思,因为不管研究者怎样努力(而且他们确实非常努力),很少有架构能胜过经过精心调节的 LSTM。但是,人类记忆的工作却与 LSTM 完全不同。当我们在处理日常生活中的任务时,我们会回忆和关注与场景相关的特定记忆,很少有其它内容。比如当我回家并开车到当地的杂货店时,我会使用我在这条道路上驾驶了数百次的记忆,而不是如何从 Camden Town 驱车到伦敦的 Piccadilly Circus 的记忆——即使这些记忆刚刚才加入我的经历,仍然活灵活现。就此而言,人类的记忆基本都是根据场景进行查询的——取决于我们在哪里以及做什么,我们的大脑知道哪些记忆对我们有用。
在深度学习中,这一观点催生了外部的基于关键值的记忆。这并不是一个新思想;神经图灵机(,这是我读过的第一篇而且是最喜欢的论文)使用了一种可微分的外部记忆存储来增强神经网络,可以通过指向特定位置的向量值的「读」和「写」头来访问。我们可以很容易想到将其扩展到强化学习领域——在任意给定时间步骤,智能体都会获得其环境观察和与当前状态相关的记忆。这就是近期的 MERLIN 架构的所做的事情:。
MERLIN 有两个组件:一个基于记忆的预测器(MBP)和一个策略网络。MBP 负责将观察压缩成有用的低维「状态变量」,从而将其直接存储到键值记忆矩阵中。它也会负责将相关的记忆传递给策略网络,然后策略网络会使用这些记忆和当前状态来输出动作。
这个架构可能看起来有些复杂,但要记住,其策略网络只是一个输出动作的循环网络,而 MBP 也仅做三件事:
将观察压缩成有用的状态变量 z_t,从而传递给策略。
将 z_t 写入记忆矩阵
获取其它有用的记忆并传递给策略
其工作流程看起来是这样的:输入的观察首先被编码并被输入一个 MLP,这个 MLP 的输出会被添加到下一个状态变量的先验分布上,从而得到后验分布。这个后验分布基于所有之前的动作/观察以及新的观察,然后会被采样以产生一个状态变量 z_t。接下来,z_t 会被输入 MBP 的 LSTM,其输出会被用于更新先验分布以及通过向量值的「读取键」和「写入键」来对记忆进行读取/写入——这两者是以作为 LSTM 的隐藏状态的线性函数得到的。最后,下游的工作是策略网络使用 z_t 以及从记忆读取的输出来得出一个动作。
其中一个关键细节是:为了确保状态表征有用,MBP 也经过了训练以预测当前状态 z_t 的奖励,这样所学习到的表征就与当前任务存在关联。
MERLIN 的训练有一些复杂;因为 MBP 的目标是用作一种有用的「世界模型」,这是一个难以实现的目标,所以它实际上的训练目标是优化变分下界(VLB)损失。(如果你不熟悉 VLB,可以参考这篇文章:-lower-bound/ ;但就算你不理解,也不妨碍你理解 MERLIN。)这个 VLB 损失包含两个成分:
在这下一个状态变量上的先验和后验概率分布之间的 KL 距离,其中后验分布还额外有新观察的条件。最小化这个 KL 距离能确保新状态变量与之前的观察/动作保持一致。
状态变量的重构损失;我们试图在这个状态变量中重现输入的观察(比如图像、之前的动作等)并基于该状态变量预测奖励。如果这个损失很小,说明我们就找到了一个能准确表征该观察的状态变量,而且它还可用于产生能得到高奖励的动作。
下式就是我们最终的 VLB 损失,其中第一项是重构损失,第二项是 KL 距离:
这个策略网络的损失是我们上文讨论过的 A3C 的策略梯度损失的稍微更好的版本;它使用的算法被称为「广义优势估计算法」,其细节超出了本文的覆盖范围(但能在 MERLIN 论文附录的 4.4 节找到),但其看起来就类似于下面给出的标准的策略梯度更新:
一旦训练完成,MERLIN 应该就能通过状态表征和记忆来预测性地建模世界,其策略也应该能够利用这些预测来选取有用的动作。
MERLIN 并不是唯一一个使用外部记忆存储的深度强化学习研究。早在 2016 年,就有研究者将这一思想用在了 MQN(记忆 Q 网络)中来解决 Minecraft 中的迷宫问题: ;但使用记忆作为世界的预测模型的概念具有一些独特的神经科学方面的推动力。有一篇 Medium 文章()很好地解释了这一思想,所以这里就不再重复了,只说说其关键论点:不同于对大多数神经网络的解释,我们的大脑很可能不是以「输入-输出」机器的运作的。相反,其工作类似与一个预测引擎,我们对世界的感知实际上只是大脑对于我们的感官输入的原因的最佳猜测。神经科学家 Amil Seth 对 Hermann von Helmholtz 在 19 世纪提出的这一理论进行了很好的总结:
大脑被锁在颅骨中。它所接受的都是模糊和有噪声的感官信号,这些信号仅与世界中的物体存在间接的关联。因此,感知必然是一个推理过程,其中非确定性的感官信号会与对世界的先前预期或「信念」结合起来,以构建大脑对这些感官信号的原因的最佳假设。
MERLIN 的基于记忆的预测器的目标正是实现这种预测推理。它会对观察进行编码,然后将它们与内在的先验结合起来,从而生成一个涵盖输入的某些表征(或原因)的「状态变量」,这些状态会被存储在长期记忆中以便智能体之后能基于它们采取行动。
智能体、世界模型和想象
有意思的是,大脑类似预测引擎的概念会将我们带回我们想要探究的第一个强化学习问题:如何从环境中有效地学习?如果我们不能直接根据观察得到动作,那么我们又该如何最好地与周遭环境交互并从中学习呢?
在强化学习领域,传统的做法要么是无模型学习,要么是基于模型的学习。无模型强化学习是学习直接将原始的环境观察映射到价值或动作。基于模型的强化学习则是首先学习一个基于原始观察的环境的过渡模型,然后使用该模型来选择动作。
图中外圈表示基于模型的强化学习,包含「direct RL」的内圈表示无模型强化学习。
比起无模型学习中单纯的试错方法,基于模型进行规划的样本效率要高得多。但是,学习优良的模型往往非常困难,因为模型不完美造成的误差往往会导致智能体表现糟糕。因为这个原因,深度强化学习领域内很多早期的成功研究(比如 DQN 和 A3C)都是无模型的。
话虽如此,1990 年的 Dyna 算法()就已经模糊了无模型和基于模型的强化学习方法之间的界线,其中使用了一个学习后的模型来生成模拟的经历,以帮助训练无模型策略。现在,已有研究将这两种方法直接组合到了一起,即「想象力增强的智能体」算法(I2A,)。
在 I2A 中,最终策略是一个与无模型组件和基于模型的组件相关的函数。基于模型的组件被称为该智能体对世界的「想象」,其由该智能体内部的学习后的模型所产生的想象轨迹组成。但是,其关键的地方在于基于模型的组件的末端还有一个编码器,它会将想象轨迹聚合到一起并解读它们,使得智能体能学习在有必要时忽略自己的想象。也就是说,如果智能体发现其内部模型投射的轨迹是无用的和不准确的,那么它就可以学会忽视该模型并使用其无模型分支进行处理。
上图展示了 I2A 的工作。观察一开始就会被传递给无模型组件和基于模型的组件。在基于模型的组件中,会根据在当前状态可能采取的 n 个动作来想象 n 个不同的轨迹。这些轨迹是通过将动作和状态输入其内部环境模型而得到的,从而能够过渡到新的想象状态,然后取其中能得到最大化结果的动作。一个蒸馏后的想象策略(与通过交叉熵损失的最终策略相似)选择下一个动作。经过固定的 k 个步骤之后,这些轨迹会被编码并被聚合到一起,然后会与无模型组件的输出一起输入策略网络。关键的地方在于,这种编码能让策略以最有用的解读想象轨迹——如果不合适就忽视它们,在可用时就提取出其中与奖励无关的信息。
I2A 的策略网络是通过一个使用优势的标准策略梯度损失训练的,类似于 A3C 和 MERLIN,所以这应该看起来很眼熟:
此外,在实际策略和内部模型的想象策略之间还添加了一个策略蒸馏损失,以确保想象策略选择的动作接近当前智能体会选择的动作:
I2A 的表现优于包含 MCTS(蒙特卡洛树搜索)规划算法在内的很多基准。即使在其基于模型的组件被故意设计得预测结果很差时,它也能在实验中得到出色的表现,这说明它能权衡所要使用的模型——在有必要时也会使用无模型方法。有意思的是,内部模型较差的 I2A 的表现实际上还稍微优于有较好模型的 I2A——研究者将其归因于随机初始化或有噪声的内部模型能提供某种形式的正则化,但很显然这还是一个有待进一步研究的领域。
不管怎样,I2A 都很出色,因为它在某些方面也体现了人类在世界中的运作。我们总是在根据对我们所处的环境的某个心智模型来规划和预测未来,但我们也都清楚我们的心智模型并不完全准确——尤其是当我们处在新环境中或遇到我们未曾见过的情形时。在这种情况下,我们会进行试错,就像是无模型方法一样,但我们也会使用新的经历来更新我们内在的心智模型。
目前有很多研究者都在探索如何有效结合基于模型的方法和无模型方法。Berkeley AI 提出了一种时间差分模型:;其也有一个非常有趣的前提。其思想是让智能体设置更多时间上抽象的目标,即「在 k 个时间步骤内处于 X 状态」,然后在保证最大化每 k 个步骤所收集到的奖励的同时学习这些长期的模型过渡。这能为我们提供对动作的无模型探索和在高层目标上的基于模型的规划之间的平滑过渡——如果思考一下这种方法,你会发现这又会将我们带回分层式强化学习。
所有这些研究论文都关注的是同样的目标:实现与无模型方法同样(或更优)的表现,同时达到基于模型的方法那样的样本效率。
总结
深度强化学习模型确实很难训练,这一点毫无疑问。但正是由于这样的难度,我们才提出了那么多的策略、方法和算法,以便能借助深度学习的强大力量来解决经典(或非经典)的控制问题。
这篇文章对深度强化学习的近期研究进行了不全面的介绍——还有大量研究没有提及,甚至还有很多研究我根本就不知道。但是,希望这里介绍的一些记忆、分层和想象方向的研究能够帮助读者了解我们着手解决强化学习领域内一些长期挑战和瓶颈的途径。
可以推荐几款烧脑游戏吗
你好,很高兴能够回答你的问题,今天我就来告诉你有哪些烧脑的游戏?
- 回神壁
这是一款日本游戏,掉落的黑板擦,海边的螃蟹。芥末放太多的寿司,没有纸的厕所。在这个游戏中,你只需要做的,就是救出在危难关头的主人公。这款游戏及其考验你的智商,感兴趣的小伙伴也可以去下载一下。
2. 我去!还有这种操作?
这是一款可以让你不断喊“我去!还有这种操作?”的烧脑游戏,每一个答案都让你有一种万万没想到的感觉,有些像几年前爆活的“史上最贱小游戏”。这个游戏的答案都是你想不到的。
最有意思的是,这个游戏还会出现,如下图这样的灵魂拷问。像我这样聪明的人没关都要想好久呢。
3. 别相信他的谎言
难玩指数:★★★★★
温馨提示:你在玩此款游戏的时候请不要砸掉手机!
据说是目前最难的解密游戏,被评为史上烧脑游戏之最,游戏虽然很小,但每一关都有一个似是而非的图案、声音等等,让你思考真正的答案。第二关就涉及到摩斯密码,感觉这个游戏能通关,智商都已经达到可以去FBI上班的级别了。
我在玩这款游戏的时候,我都已经怀疑我,是不是真的太蠢了。恨不得都想把手机给砸了……反正我是一关都没过,如果说第一关通过的人欢迎在评论区艾特我。
好了以上就是我今天分享的三款超级烧脑的游戏,除了前两个,我还觉得舒服些最后一个,我是真的要疯了。截止目前我是一关都没过呀。哪位大佬能在评论区指点一下?感谢您的观看。
机器人历险记78关如何通过
在机器人历险记的第78关中,玩家需要解决一个迷宫谜题。首先,观察迷宫的结构和路径,找出通往出口的最短路径。
不思议迷宫军团科技怎么拿
新科技在主线拿到扎克号后:
谁能帮忙推荐一下,好看的电视剧或电影
刚刚乐享了电视连续剧《清平乐》,所以,非常喜欢小悟空发来的这个问题邀请,也愿意与志同道合的小伙伴们一起分享《清平乐》的最佳看点,尤其是剧中“八卦”与史实的戏剧性糅合,堪称“假作真时真亦假,无为有处有还无”!#清平乐#
“宝髻松松挽就”——逆转结局
《清平乐》的大结局,夸张地铺写了以司马光为首的台谏在朝堂上公主失德內侍惑主、力谏官家赵祯杀掉梁怀吉的场面。赵祯用仁德化育,司马光以死胁迫。就在剑拔弩张的危急时刻,徽柔操纵一具悬丝傀儡,唱着“宝髻松松挽就,铅华淡淡妆成”上殿了。
徽柔所唱的词,名为《西江月》,也是一件历史“公案”,在司马光的文集里是找不到这首词的,但是赵令畤的《侯鲭录》却把这首艳词收在司马光名下。
刻板执拗的司马光在如此庄严的朝堂上,听到公主唱出自己当年写下的柔情婉转的丽词,又被公主抛过来一连串地质问:这首词你是为谁写的?那词中的女子呢?你也有过情爱吗?爱恨嗔痴都是有罪?真是以其人之道,还治其人之身!司马台谏的就这样被逆转了!
“逸马杀犬于道”——戏剧性的“张冠李戴”
这个典故确实存在,讲的是欧阳修与属下同僚之间,就所见类似剧中马逸毙犬事件的讨论,中心议题是如何言简意赅、明白晓畅地叙事说理。《清平乐》改编得很巧妙,更富戏剧性,不仅把原本为欧阳修属下同僚地表述,对应地安插给几个落第士子,而且还做了推波助澜的蓄势,把之前张妼晗让许兰苕唱的那首《望江南▪江南柳》,由刘几等士子再次唱起,却是一副油腔滑调地演绎,以此来嘲笑欧阳修的“盗甥案”,使得剧情亦庄亦谐,张弛有度。
公忠体国的包拯形象
《清平乐》中的包拯形象,你接受了吗?他没有了戏曲中的方正亮黑的色彩,没有了以往荧屏上的月亮造型,更没有了广泛流传的威风刚猛。《清平乐》中没有让包公演绎铡包勉、遇皇后、打龙袍、游五殿、断木盆的神剧,更没有铡驸马的场面。《清平乐》给了包拯回归正常臣子的形象,并且,细细品味,这个包拯更加可爱。他拉住官家的袍袖,激烈张尧佐,赵祯只是一边大呼“包倾公忠体国”,一边躲避包拯言辞飞溅;他“红杏尚书”宋祁,官家就把宋祁外放,直接把他按到三司使的位置上,包拯一句“老臣一切出于公心啊”,不只是赵祯笑了,乾隆娣也觉得好笑,轻松,可爱!
一出好戏,如果不用求全责备的心态来观赏,总有你乐见的看点。《清平乐》有更多值得欣赏之处。乾隆娣愿与志同道合的小伙伴们一同观赏,一同评点哦!